Calibration de modèles épidémiques grâce au transport optimal et à l’optimisation sans dérivation


Calibration de modèles épidémiques sur des graphes grâce au transport optimal et à l’optimisation sans dérivation
Calibration de modèles épidémiques sur des graphes grâce au transport optimal et à l’optimisation sans dérivation
Les modèles de propagation de pathogènes chez l’animal reposent sur des simulations complexes combinant dynamiques d’infection et interactions spatiales entre de nombreux individus. La calibration de ces modèles est difficile, car elle nécessite de comparer des sorties simulées à des données souvent incomplètes et hétérogènes dans l’espace et le temps. Les approches actuelles reposent sur des comparaisons indirectes ou des manipulations intermédiaires des simulations, ce qui limite leur robustesse. Ce projet vise à développer de nouvelles méthodes de calibration, exploitant la théorie du transport optimal, afin de mieux prendre en compte la complexité des phénomènes épidémiques et spatiaux.
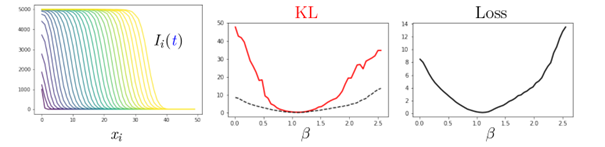
Comparaison de deux mesures d’écart pour des données simulées. La divergence de Kullback–Leibler (KL) est calculée uniquement sur les nœuds observés, tandis que la mesure de dissimilarité proposée (Loss) prend en compte l’ensemble de l’évolution simulée sur tous les nœuds du réseau. À gauche : évolution du nombre d’individus infectés dans un réseau de fermes disposées sur une ligne. Chaque couleur correspond à un instant différent. Le paramètre bêta contrôle la vitesse de propagation du front. Au centre et à droite : évolution des mesures de dissimilarité entre les sorties du modèle et les données simulées en fonction de bêta. La méthode proposée induit un profil plus convexe, facilitant l’identification du minimum correspondant à la valeur estimée de bêta.
Questions et outils mathématiques
La propagation de pathogènes dans les élevages est modélisée à plusieurs échelles. Au sein des fermes, des modèles décrivent les états d’infection des individus, tandis qu’entre fermes, la transmission est représentée par un réseau reliant les fermes selon leur proximité géographique et leurs échanges commerciaux. Les données disponibles consistent typiquement en des mesures du nombre de nouveaux cas dans certaines fermes du réseau, obtenues en testant une fraction des animaux à des instants donnés. Ce projet cherche à déterminer comment comparer ces observations partielles aux prédictions du modèle, tout en prenant en compte la structure du réseau, et si cela peut conduire à des procédures de calibration plus efficaces et plus robustes.
Pour cela, un modèle d’observation simplifié a été introduit. Celui-ci représente le fait qu’un cas détecté dans une ferme a pu en réalité provenir d’une ferme voisine, avec une probabilité décroissante selon la distance dans le réseau. Cette flexibilité permet de comparer les observations et les prédictions même lorsque le modèle ne prédit aucun cas là où un cas a été détecté, ce qui est fréquent avec des données partielles.
La vraisemblance associée à ce modèle fournit une mesure de dissimilarité naturelle entre simulations et observations partielles. Son calcul exact est difficile, mais elle peut être approchée par un problème de transport optimal, qui consiste à trouver la meilleure manière d’associer les observations aux fermes du réseau, et qui se résout efficacement par des techniques d’optimisation convexe. Cette approche ouvre la voie à des procédures de calibration applicables à de grands réseaux, y compris lorsque les données disponibles sont rares ou irrégulières.
Premiers résultats et perspectives
L’approche développée dans ce projet permet de quantifier l’écart entre simulations épidémiologiques et données incomplètes. Elle s’est révélée particulièrement pertinente lorsque la dynamique est dominée par la propagation de fronts d’infection. Dans ce cas, l’intégration d’effets spatiaux dans la mesure de dissimilarité rend le problème d’estimation des paramètres mieux conditionné et donc plus facile à résoudre.
Ces observations ont été faites sur des modèles de petite taille, mais il reste à déterminer si ces avantages se maintiennent dans des configurations plus complexes et à plus grande échelle. Par ailleurs, le calcul de la vraisemblance introduite implique des coûts de calcul supplémentaires. Il reste à évaluer si ce surcoût est compensé par les gains en efficacité et en robustesse de la méthode.
Ce projet interdisciplinaire a permis le financement du post-doctorat de Clément Sarrazin, à présent maître de conférences à l’IMT Nord Europe de Lille.






